|
| |
|
|
|
 | | Component services | |
|
|
This section describes the E1 services, which extend the distributed object model to a full-featured component model. Among these are Object Registry, Access Control Server, Global Naming Server, and garbage collection system.
|
|
|
|
| | Object Registry | |
|
|
Object Registry lies at the heart of the E1 component model. It maintains the information about all local replicas of distributed objects, including their types, virtual addresses, host domain IDs and reference counting information. The Registry coordinates execution of such operations as creation and deletion of the distributed objects and their replicas, crossdomain calls and garbage collection.
Creating and deleting objects
Distributed objects in E1 are created by means of the CreateObject method, exposed by Object Registry. It accepts class name, target domain identifier and, optionally, the name of the replication strategy to be applied to the new object. CreateObject method performs the following sequence of operations:
- If the required class object does not exist in the target domain, it will be loaded from Class Repository.
- Calls the class object to create a semantics object. Since the new distributed object is represented only in one node, it does not require a replication object.
- Registers the new object in internal Object Registry data structures. The caller of CreateObject method obtains the first strong reference on a new object.
- Registers the new object in global naming system.
- Returns the pointer to one of the newly created object's interfaces.
Distributed object is automatically destroyed when all of its replicas turn to garbage >>. One can also force the destruction of an object by calling the DeleteObject method of Object Registry.
Creating replicas of existing distributed objects
The newly created distributed object consists of only one replica. Subsequently more replicas can be created and destroyed. Replica creation is initiated when a strong reference on a distributed object is created in the node where there is no replica of the given object yet >>. Object Registry then performs the following sequence of operations:
- Obtains information about the object from the global naming system: its class name, contact points and replication strategy.
- Loads the class objects for semantics and replication objects to be created, from Class Repository to target domain.
- Creates a semantics object and the associated replication object.
- Initializes replication object with the list of contact points, required to execute a group join protocol. This protocol is a part of the replication strategy.
Crossdomain calls validation
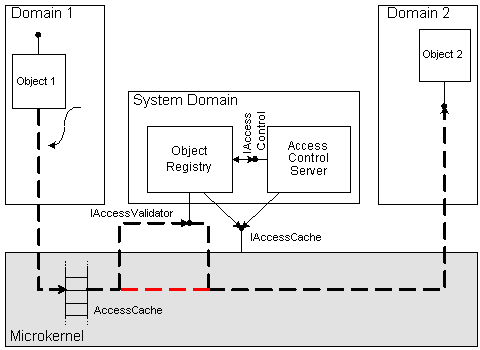
At the time of crossdomain call, the microkernel refers to the Object Registry through an IAccessValidator interface to assure the existence of the invoked object's replica in a local node, and also to validate the caller's rights to perform the given operation.
The Registry itself does not implement access control policy. Instead, for the verification of call legitimacy it refers to the Access Control Server, which will be discussed in the next section >>.
To improve the efficiency of crossdomain communication, information on objects and rights can be cached by the microkernel, which avoids having to look up the Registry for each crossdomain call. In figure an optimized crossdomain call path is shown with red dashed line. Cache consistency is maintained by the Object Registry through the IAccessCache interface.
Communication between microkernel and Object Registry during crossdomain call. The dashed line shows normal and optimized (red) crossdomain call path.
Other important Object Registry functions - reference management and garbage collection are described below.
|
|
|
|
| | Access Control Server | |
|
|
Access Control Server (ACS) is a distributed object, which enforces a single access control policy across the distributed system by verifying the legitimacy of each call.
Selection of an operating system access control model is very challenging task. Having its own limitations and drawbacks, none of the existing protection models can be considered generally optimal. Therefore E1 does not impose any specific access control policy to be implemented by ACS. Nor does it limit the ACS replication strategy or data structures used to store information on rights. However, the ACS must implement the IAccessControl interface, used by the Object Registry for crossdomain calls validation. The main method of the IAccessControl interface, namely ValidateAccess, confirms or denies the validity of a call, based on: the thread identifier, caller and callee identities, and the invoked method.
ACS can also expose additional interfaces, depending on the particular access control model it implements. For example, ACS, implementing Take/Grant capability model [7, 8], can provide Take, Grant and Revoke methods, while emulation of UNIX access control list model would require methods like Chown and Chmod.
Global fulfillment of access control rules is provided by the ACS replication strategy. For example, on capability revocation, corresponding notification must be delivered to all ACS replicas, which contain outdated information. The overhead introduced by ACS replication is one of the important factors to be considered when selecting an access control model.
A variety of protection models can be implemented within the framework of the presented approach, including various capability [56, 20, 24, 7] and access control list (ACL) [42] models. It is also possible to select subjects and objects of the model in different ways. Some possible choices for objects are: distributed object, a single interface or even method. While for the role of subjects, one can use distributed object, protection domain or user. The last possibility is rather interesting. Until now, we have not introduced user abstraction in E1. Nevertheless, the models in which rights belong to users or roles are in wide use today [44, 42]. In such models each thread operates on behalf of some user. Therefore, though the concept of users is not explicitly supported in E1, it is possible to implement it at the ACS level by associating users with groups of threads.
|
|
|
|
| | Global Naming Server | |
|
|
The Global Name Server (GNS) implements a distributed object location protocol, which maps the object's virtual address to the list of its contact points, i.e. network nodes, containing the object's replicas. GNS is used by the Object Registry, on creation of a new distributed object replica in a local node.
The choice of a specific object location algorithm, implemented by GNS, should be based on the scale of the system and on the frequency with which nodes join and leave it. For small systems a centralized protocol with one or several name servers is preferable. For large-scale systems with stable structures the hierarchy of domain servers [34] is usually used. While for highly dynamic systems decentralized naming protocols, e.g. [51], are most effective.
|
|
|
|
| | Garbage collection | |
|
|
The purpose of the E1 garbage collection system is to detect and destroy unused distributed object replicas.
In conventional operating systems there is normally no need for a separate garbage collection subsystem. Instead, every operating system component uses its own resource management mechanism, based on a simple reference counting. Such approach is easy to implement and it results in minimal overhead. However, in an asynchronous distributed environment, reference management becomes a substantially more complicated task [38]. In E1 it is further complicated by the possibility of having several object replicas in different nodes. Garbage collection in such systems requires sophisticated distributed algorithms and data structures. Since it is inefficient to design and implement them separately for each operating system component, E1 provides a single garbage collection system for all distributed objects.
Garbage collection in E1 is based on the analysis of a reference graph between distributed objects replicas. Two types of references correspond to two types of object interaction: local interaction between replicas of different distributed objects, and remote interaction between replicas of a single distributed object within its replication strategy. Correspondingly, there are local references between different distributed objects and remote references between replicas of one object.
We will also distinguish week and strong references. Weak reference is simply a pointer to an interface of an object or RPC-pointer to one or several remote replicas, used to perform local and remote invocations, respectively. Weak references are not traced by garbage collection system or taken into account while detecting unused object replicas. To convert a weak reference to a strong reference, one must execute AddRef operation over it. In E1, AddRef method is exposed by the garbage collection system, rather than the object itself. As a result of the AddRef operation, new strong reference is registered in the garbage collection system. If the replica addressed by the given reference does not exist yet, it is created by the Object Registry, as described in >>. Every subsequent AddRef operation increments the value of a counter, associated with the given reference. The counter is decremented by the Release operation. When it drops to zero, the strong reference is deleted. Deleting the last strong reference to the replica initiates the replica's removal.
In each node, the garbage collection system maintains only the information concerning local replicas. For each replica, the list of strong references on it, as well as the list of references it holds to other replicas, is stored. Both distributed and local references are taken into account. This information is sufficient to trace any changes in the reference graph, including those caused by node or network connection failures, while the simple references counting does not account for such situations correctly.
The majority of information about the references is stored in the Object Registry. Registries in different nodes communicate in order to manage remote references. Besides the Object Registry, the E1 garbage collection system includes Reference Monitors located in each domain. Reference Monitor carries out reference counting within its domain, which minimizes the number of crossdomain calls to the Registry. It exposes the IRefMonitor interface, containing AddRef and Release methods. To create and delete local references, application objects interact with Reference Monitor, which, if necessary, calls the Object Registry reference management methods.
Cyclic distributed garbage collection in E1 is based on the partial reference graph tracing procedure, which verifies the reachability of some specified replica from Root Object Set [58]. The Root Set consists of system objects, which by definition are never regarded as garbage. All objects reachable from ROS are not garbage either. All other objects are considered garbage. To perform partial reference graph tracing, a suspect replica must be selected using some heuristic procedure. This replica will become a starting point for graph scanning. As a result, either reachability of the given replica from the ROS will be proven, or a set of replicas forming the garbage cycle will be detected.
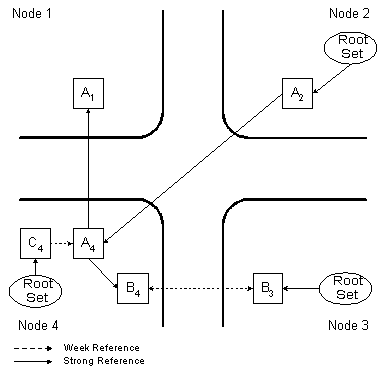
Figure shows a reference graph fragment. Solid arrows denote strong references, while dashed arrows correspond to weak references. For the distributed object A the client/server replication strategy with one primary and one backup server is used. Client replica A2 holds strong reference on primary server replica A4, which maintains the object state and performs operations upon it. In its turn, A4 holds the strong reference on the backup server A1, which stores a secondary copy of the state. Client A2 forwards all method calls to primary server A4, while A4 communicates with backup server A1 to keep it in a consistent state.
Object B uses an active replication strategy. Each method invocation is broadcasted to all replicas, which perform corresponding operations over the local copy of object state. To execute these remote invocations, each replica holds weak references on all other replicas (in the figure, object B has only two replicas). In the case of active replication each replica has to exist only as long as it is used in its local node, and can be safely destroyed afterwards, i.e. replicas do not depend on each other. Hence, no replica needs to hold strong reference on any other replica.
Reference graph fragment.
This example clarifies the semantics of strong and weak references. Strong reference reflects the dependent relationship between replicas, that is when some replica (or object) requires another replica (or object) for its correct operation. Weak reference is simply a means of interaction. It is used when communicating replicas do not depend on each other, and therefore destruction of one does not cause the other to malfunction.
|
|
|
| |
|
| |