|
Distributed objects are first-class citizens in E1. All operating system services, as well as application software are constructed from distributed objects.
All objects reside in a single virtual 64-bit address space >>. Each object exposes one or several interfaces consisting of a set of methods. Each distributed object interface is identified by its unique 64-bit address. Any object, knowing this address, can invoke methods of the interface from any network node. All interfaces in E1 contain a standard method of navigation between the interfaces of the same distributed object.
Objects in E1 can be physically distributed, i.e. keeping partial or complete copies of the state in several nodes. The copy of an object's state in one of the system nodes is called distributed object replica. The distribution of the state among replicas and replica synchronization is called object replication.
The E1 distributed object architecture aims to separate an object's semantics and replication strategy. An object developer implements only the object's semantics or functionality in local (non-replicated) cases, while a replication strategy supplier implements the replication algorithm. Replication strategy can be universal, i.e. applicable to objects of various classes. At the same time, objects of the same class can be replicated using different strategies.
To achieve the goal above, we put forward the distributed object architecture, in which object semantics and replication strategy are implemented by separate structural units. In E1, distributed objects are composed of local objects. A local object is limited to one node of the distributed system. Note that a similar distributed object architecture has been implemented by Globe object-oriented middleware [50].
The E1 local object resembles the structure of a C++ object [52]. It consists of a fixed-size section, containing data members and pointers to interfaces (method tables), and the data structures, dynamically allocated by the object from heap. In terms of C++, the interfaces of the local object are purely virtual base classes, from which the object is inherited. A similar approach is taken by COM [33].
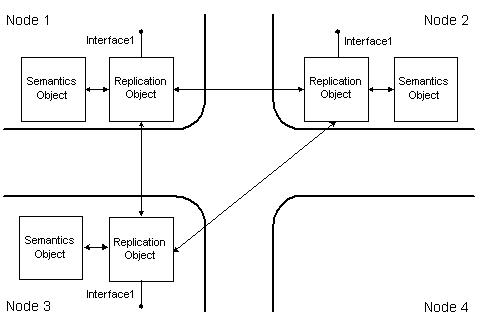
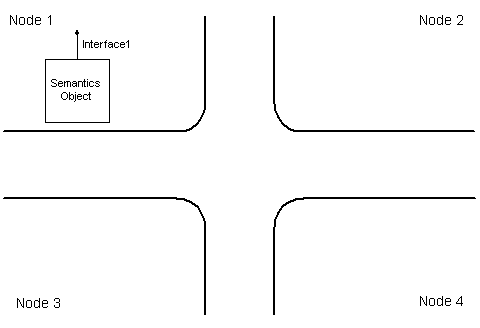
The following figure shows architecture of distributed object
(a)
(b)
The distributed object architecture. a. distributed object with one replica; b. distributed object with several replicas
In a trivial case when the distributed object has only one replica (a), it is identified with a single local object, semantics object. Semantics object contains the distributed object state, exposes the distributed object interfaces and implements its functionality.
When the reference on the distributed object is created (>>) in the node, where there is no replica of the given object yet, a new replica is created in this node. The structure of distributed object with several replicas is shown in Figure 1b. A copy of the semantics object is placed in each node, where the distributed object is represented. To ensure global accessibility of the distributed object interfaces by their virtual addresses, semantics objects are placed to the same virtual memory location in all nodes. The distributed object integrity is maintained by replication objects, complementing the semantics objects in each node. Replication objects implement the distributed object replication protocol. Replication object substitutes implementations of semantics object interfaces by its own implementations, which allows it to process the distributed object method invocations . While processing the invocation, replication object can refer to the semantics object to execute necessary operations over the local object state, as well as communicate with remote replication objects to perform synchronization and remote execution of operations. Interface substitution is transparent for other objects and can be thought of as aggregation of the semantics object by the replication object. Such architecture eliminates the overhead of supporting replication objects for the distributed objects that are not actually distributed, i.e. have only one replica. If an object with several replicas eventually remains with only one replica, its replication object is destroyed.
The presented distributed object architecture has two important advantages. First of all, it effectively separates the object's semantics and replication strategy. Secondly, it does not impose any essential limitations on replication algorithms used. Hence, for each object the access protocol, providing high efficiency, while preserving required reliability guarantees, can be applied.
|