|
| |
|
|
|
 | | Replication | |
|
|
In E1 the efficiency of the access to distributed object is determined by its replication strategy. The most efficient strategy is usually the one that takes into account the properties of particular object or object category. To enable the use of such strategies, E1 does not impose any limitations on the internal architecture of replication object, neither on replication algorithms used. Instead, it provides a set of services, helping developer to solve the most complicated tasks, arising from implementation of the majority of replication strategies.
|
|
|
|
| | Survey of replication strategies | |
|
|
This section provides brief description of several widely used classes of replication algorithms, which form the basis of the E1 library of replication strategies. The purpose of this section is to present an introduction to object replication. For a detailed description of various strategies, the reader may consult the following papers [9, 5, 28, 16, 2, 57, 19, 26].
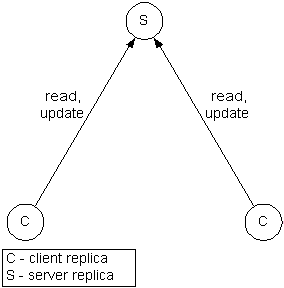
Client/server replication
Client/server is a trivial replication strategy. A single copy of the object state is maintained by a server replica. Other replicas are clients. All client invocations are forwarded to the server.
Client/server replication
This strategy is in most cases inefficient, since it does not provide local access to resources. Another disadvantage is low reliability due to centralized access to objects.
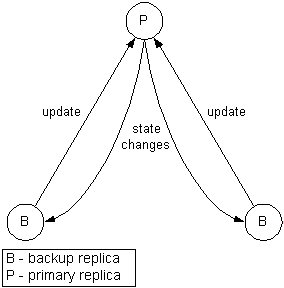
Passive replication
In the case of passive replication [9, 5] each replica stores a copy of an object state. One replica is assigned as primary. Read operations are executed locally in each node. Modifications are forwarded to the primary replica, which executes the required operations and updates all other replicas.
Passive replication
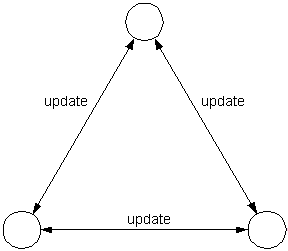
Active replication
Each replica stores a copy of an object state. Both read operations and modifications are performed locally in each node. To ensure replica consistency modifications are broadcasted to all replicas.
Active replication
Within the framework of active replication a variety of algorithms, providing different types of replica consistency (sequential consistency [28, 16], causal consistency [2], temporal consistency [57], weak consistency [19], and lazy consistency [26]), have been developed.
Migration
Migration in E1 refers to the transfer of object replica between nodes. Migration is not an independent replication strategy. It is used in conjunction with other strategies to improve the efficiency of access to resources by means of load balancing.
Migrating a replica, without any threads running in its context, is a rather trivial task. However, it is sometimes necessary to migrate replicas of objects which have methods that execute for a long time or even for the object's entire lifetime. The E1 port of a traditional UNIX program is the example of such an object. Its main() method is called right after the object is created and executes until the object is destroyed. Such an object must be moved to a remote node, along with all the threads that are executing within it. As mentioned in >>, E1 provides for such a capability.
|
|
|
|
| | Distributed object replicas communication | |
|
|
Any non-trivial replication strategy requires some communication layer to organize the interaction between distributed object replicas. In E1, such a layer is provided by the Group RPC (GRPC) service, supporting transparent invocation of remote replication objects. GRPC in turn relies upon the Group Communication mechanism which supports the exchange of unicast and multicast messages with various delivery ordering and reliability properties.
Group communication mechanism
For the purpose of this discussion, a group is a communication-level abstraction, which corresponds to a set of a single distributed object's replicas. The E1 group communication system includes two main services: group membership service and message delivery service.
Group membership service maintains consistent group membership lists, or views, for all object replicas. It allows replicas to join and leave the group dynamically. In addition, it is responsible for maintaining the consistency of the group in the face of hardware and software failures, which might cause replicas destruction or group fragmentation. This is a nontrivial task, since in an asynchronous distributed environment it is impossible to distinguish a node crash from temporary inaccessibility caused by network delays [41]. To overcome this obstacle, one can use a distributed algorithm, determining accessible group members and reaching a consensus concerning a new group structure among its surviving members [45]. Such an algorithm is implemented by a special membership service component Failure Detector (FD).
If some of the group members become inaccessible as a result of network partitioning, rather than node failures, group fragmentation occurs. In this case, group membership service initiates formation of a new group in each fragment. Later on, the fragments may merge into a single group again.
Message delivery service provides primitives for exchanging unicast and multicast messages between group members. For each message session, the delivery protocol properties can be specified. The most important ones are reliability of delivery and message ordering. The following table summarizes some possible values of these properties.
|
Property
|
Description
|
|
DELIVERY RELIABILITY
|
|
Unreliable delivery
|
Does not provide any message delivery guarantees.
|
|
Atomic delivery
|
Guarantees that each message will be either delivered to all its destinations, or to none of them
|
|
DELIVERY ORDERING
|
|
Unordered delivery
|
Does not impose any restrictions on message delivery order
|
|
FIFO-ordering
|
All messages from a group member are delivered in the order in which they were sent
|
|
Causal ordering
|
Preserves causal relations [27] between messages
|
|
Total ordering
|
Each member receives all messages in the same order
|
Message delivery properties
The development of a group communication system from scratch is a rather complicated task, which comprises implementation of message delivery and group membership algorithms. Therefore, we plan to build the E1 group communication system on one of the existing implementations. Currently the services described above are implemented in a number of group communication systems [6, 40, 3]. Such systems are designed to provide replication support within more complex software systems. Therefore they can be relatively easily integrated into E1. Also, being highly modular, they can be easily extended to support new message delivery properties [40].
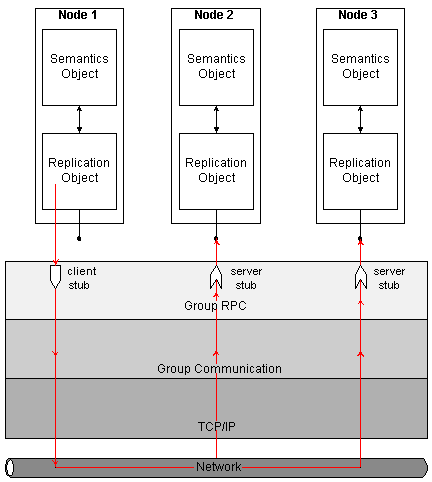
Group RPC
Message-oriented communication primitives form the basis for distributed object replicas interaction. However, it is desirable to provide the replication strategy developer with a more convenient procedural model, allowing direct access to methods of the remote replication objects. In the case of point-to-point communication, the remote procedure call (RPC) mechanism is generally used to invoke operations on remote objects. The group remote procedure call (GRPC) is the generalization of RPC for the case of multicast communication. On the basis of group communication services described above, the GRPC implements a single primitive allowing a simultaneous invocation of several remote objects. Figure depicts the architecture of E1 GRPC mechanism.
Execution of the remote call by GRPC system
Like regular RPC, GRPC implements remote invocation with the help of client and server stubs. Stubs are compiled automatically from the IDL-definitions of objects (see >>). Client stubs locally expose interfaces of remote replication objects. Each call to a client stub is converted into a message, sent to one or several remote replicas by means of a group communication system. The message is delivered to a server stub, which transforms it into a call of an appropriate replication object method. The result of the invocation is sent back to the caller's client stub. Having obtained the necessary number of responses (determined by the semantics of the call), the client stub returns control to the calling object.
|
|
|
|
| | Change of group structure | |
|
|
As discussed in the previous section, the group structure can change either when new replicas join or leave the group, or as a result of communication or node failures. On the level of group communication system such events are handled by group membership service, which delivers consistent views to all replicas. The group communication system, then, notifies replication objects about the changes in the distributed object structure through the IReplicaGroup callback interface. On the level of replication strategy, the handling of this event can involve distributed communication between replication objects, including replica synchronization, creation and deletion of the remote references and even creation or destruction of replicas. This process yields a new distributed object configuration, which meets the consistency requirements, imposed by the replication strategy used.
The following sample scenario of distributed object recovery after network partitioning illustrates that the distributed protocol which is handling the changes in group structure is an essential part of any replication strategy.
Initially, an object consists of client replica C, primary server P and backup server B (Figure a). The arrows indicate strong references between the replicas. As a result of the network partitioning the object divides into three fragments (Figure b). If the replication strategy does not provide for a future fragment re-attachment and doesn't apply any special efforts to preserve object integrity, all object replicas will be destroyed: server replicas (P and B) will be destroyed by the garbage collection system, since there are no strong references on them; while client replica must self-destruct, since it does not store a consistent copy of the object state and therefore cannot successfully process incoming method calls. Suppose however, that replication strategy tolerates object fragmentation in the following way: in order not to be destroyed by the garbage collection system, the primary server replica creates a strong reference on itself from the Root Set (Figure c). Additionally, since the given replication strategy implies the existence of a backup server with a secondary copy of the object state, the primary server creates this backup replica. All invocations of a client replica will return an error indicating that the object is currently fragmented. Thus, only the secondary server B will be destroyed as garbage. If the network connection is subsequently restored, the surviving object replicas will remerge (Figure d) and continue normal operation.
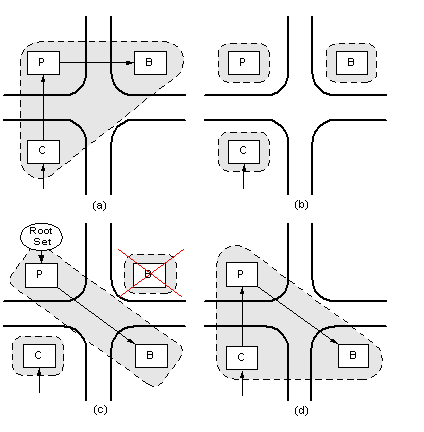
Fragmentation of the distributed object
Note that immediately after fragmentation (Figure b), replicas P and B could be destroyed as garbage. In order to process these kinds of situations correctly, the notion of transitional distributed object state is introduced. As soon as the group communication system notifies the replication object of a view change, the replica is transferred into a transitional state in which it cannot be destroyed by the garbage collection system. While in transitional state, the object can freely change its structure. For example, the object can adjust strong references between replicas or create external references, as in the example above. As soon as all required operations are complete, the object will leave the transitional state.
|
|
|
|
| | Serialization interface | |
|
|
This section discusses another important aspect of the distributed object development - implementation of the serialization interface. All replication strategies rely on some operations, which replication object can execute only in cooperation with the semantics object. The most important examples are serialization and deserialization of an object state. Almost all replication strategies employ these operations to transfer object state between the replicas and to synchronize replicas. Since the replication object is generally unaware of the structure of the semantics object, the semantics object must implement serialization operations itself. These operations are exposed to replication object through the ISerializable interface. ISerializable is similar to the CORBA Checkpointable interface, which also supports object replication [35].
In other words, the serialization of the distributed object state is delegated to the semantics object developer. Note that the serialization/deserialization procedures are generally rather cumbersome. It is therefore desirable to generate them automatically. This is an intricate problem, with no general solution, that would work efficiently for all types of objects while being language-independent.
Some languages, e.g. Java and C#, provide support for automatic object serialization and deserialization, based on run-time type information. We expect that these languages will be widely used for application programming in E1.
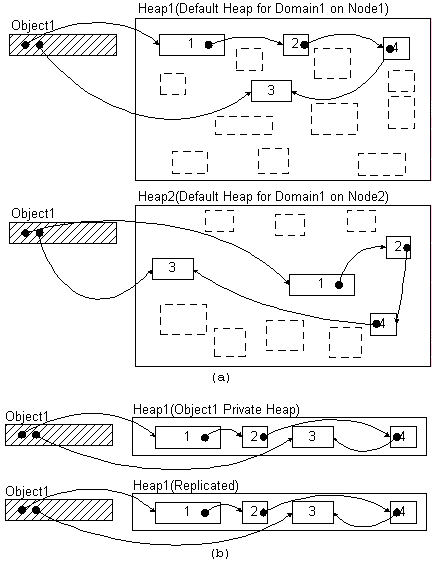
However, along with them, other languages, in particular, C++, should be supported, for which automatic object serialization is not generally possible either at the time of compilation, or at run-time [48]. It is therefore desirable to develop a language-independent method for generation of the serialization interface. In E1, the support for automatic objects serialization is provided by the memory management system. Each local object consists of a static part and dynamically allocated data part. The dynamic memory allocation interface is provided by Heap objects. Heap object represents a continuous virtual memory area, upon which allocation and deallocation operations are defined. Each domain provides the default local heap, which can be used by all its objects. Besides, any object can create a separate heap and allocate memory only from it. To serialize such an object, it is enough to store the structure of the heap plus the object's static part in some data packet. On object deserialization, the heap is restored in a new node in the same virtual address. So, the problem of serialization and deserialization of the semantics object is reduced to a far simpler problem of serialization and deserialization of a Heap object. This approach is language-independent and can be used for objects of any type. However, it introduces a memory overhead, since using a separate heap per object implies that the object's dynamic data occupies an integral number of physical memory pages.
The following figure compares two approaches. Figure a shows the serialization of the object, developed in a programming language with run-time type information support. Such object uses a default heap for dynamic memory allocation. To perform object serialization, language run-time components parse its structure by tracing the intra-object reference graph. On deserialization, the object structure is restored in the target node's default heap. This procedure preserves the object's referential integrity, while separate object fragments are placed at virtual addresses, distinct from their original ones. Figure b shows the serialization of the object, written in C++, and using private heap for memory allocation. After deserialization all object fragments are allocated at their original virtual addresses.
Two approaches for automatic serialization and deserialization of the semantics object. a. Using language run-time support. b. Using a private heap for dynamic memory allocation.
If the programming language does not support automatic serialization of the object state, and if the use of a private heap for each object results in an unacceptable waste of the physical memory, then the object developer should implement ISerializable interface himself. This approach will be used for the E1 system objects.
|
|
|
| |
|
| |